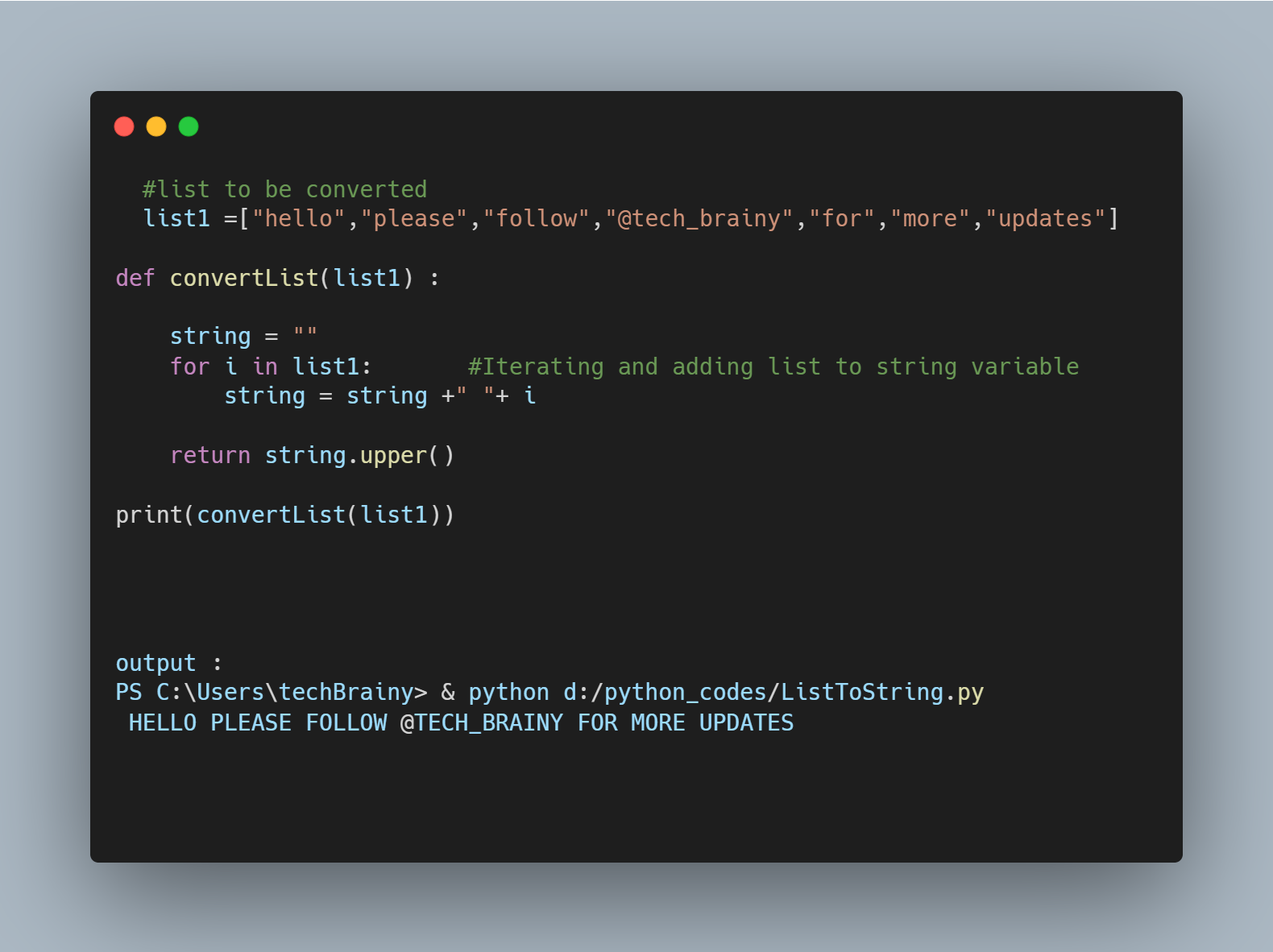
Python Convert Dict To List: ทดลอง Mcu Board Stm32F4: การใช้ Dict ใน Python
Natural language processing หรือ การประมวลภาษาธรรมชาติ โมดูล PyThaiNLP เป็นโมดูลที่ถูกพัฒนาขึ้นเพื่อพัฒนาการประมวลภาษาธรรมชาติภาษาไทยในภาษา Python และ มันฟรี (ตลอดไป) เพื่อคนไทยและชาวโลกทุกคน! เพราะโลกขับเคลื่อนต่อไปด้วยการแบ่งปัน รองรับเฉพาะ Python 3. 4 ขึ้นไปเท่านั้น ติดตั้งใช้คำสั่ง pip install pythainlp วิธีติดตั้งสำหรับ Windows ให้ทำการติดตั้ง pyicu โดยใช้ไฟล์ จาก หากใช้ python 3. 5 64 bit ให้โหลด PyICU‑1. 9. 7‑cp35‑cp35m‑ แล้วเปิด cmd ใช้คำสั่ง pip install PyICU‑1.
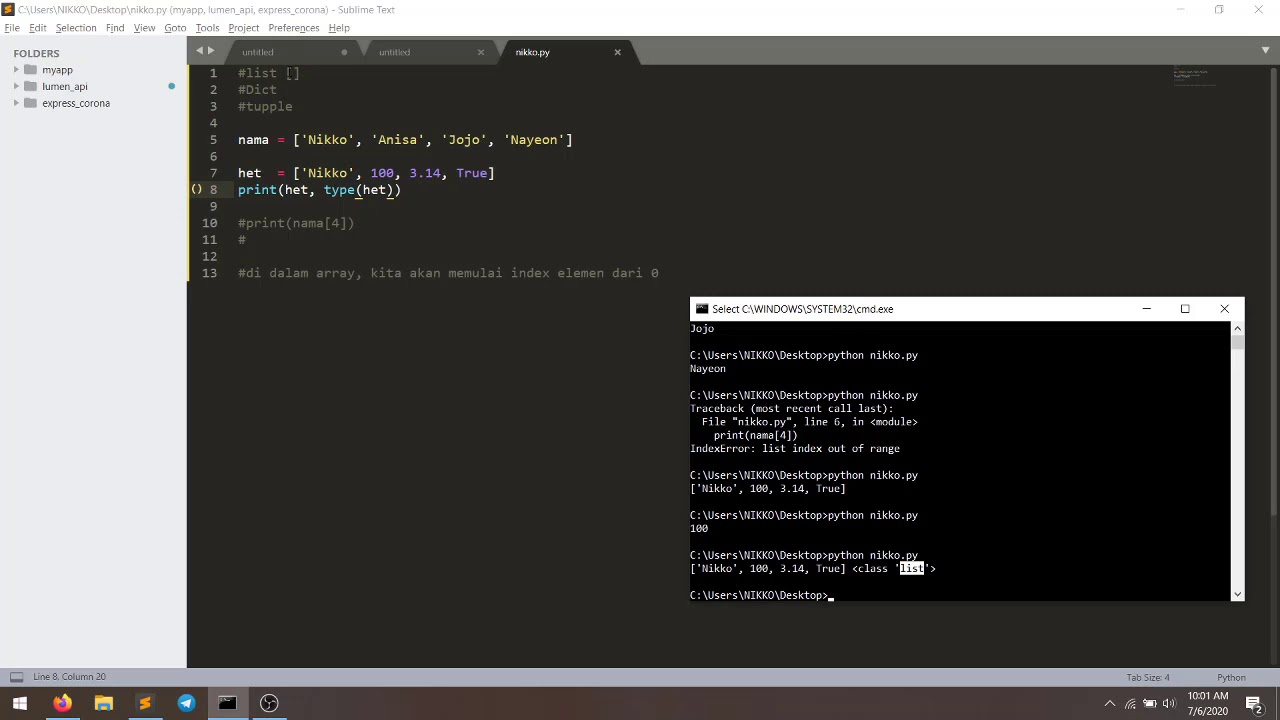
- ทดลอง MCU board STM32F4: การใช้ dict ใน Python
- Ping หา ip card
- บริษัท ไปรษณีย์ไทย จำกัด ThailandPost
- เหรียญ sand คือ
ทดลอง MCU board STM32F4: การใช้ dict ใน Python
Ping หา ip card
- จาก บุรีรัมย์ ไป กรุงเทพ
- อุจจาระเป็นเลือด - neurosun
- ย้อม ผม เขียว
- หัวหน้า คืออะไร แปลภาษา แปลว่า หมายถึง (พจนานุกรมไทย-ไทย ราชบัณฑิตยสถาน)
- American bully ราคา movie
- วิทยาลัยเทคนิคมหาสารคาม รับสมัครครูอัตราจ้าง จำนวน 5 อัตรา
- เข็มขัด ผู้หญิง gucci
- Hacksaw ridge หนัง
- รายการ efm on tv
บริษัท ไปรษณีย์ไทย จำกัด ThailandPost
ทดลอง MCU board STM32F4: การใช้ dict ใน Python
เหรียญ sand คือ
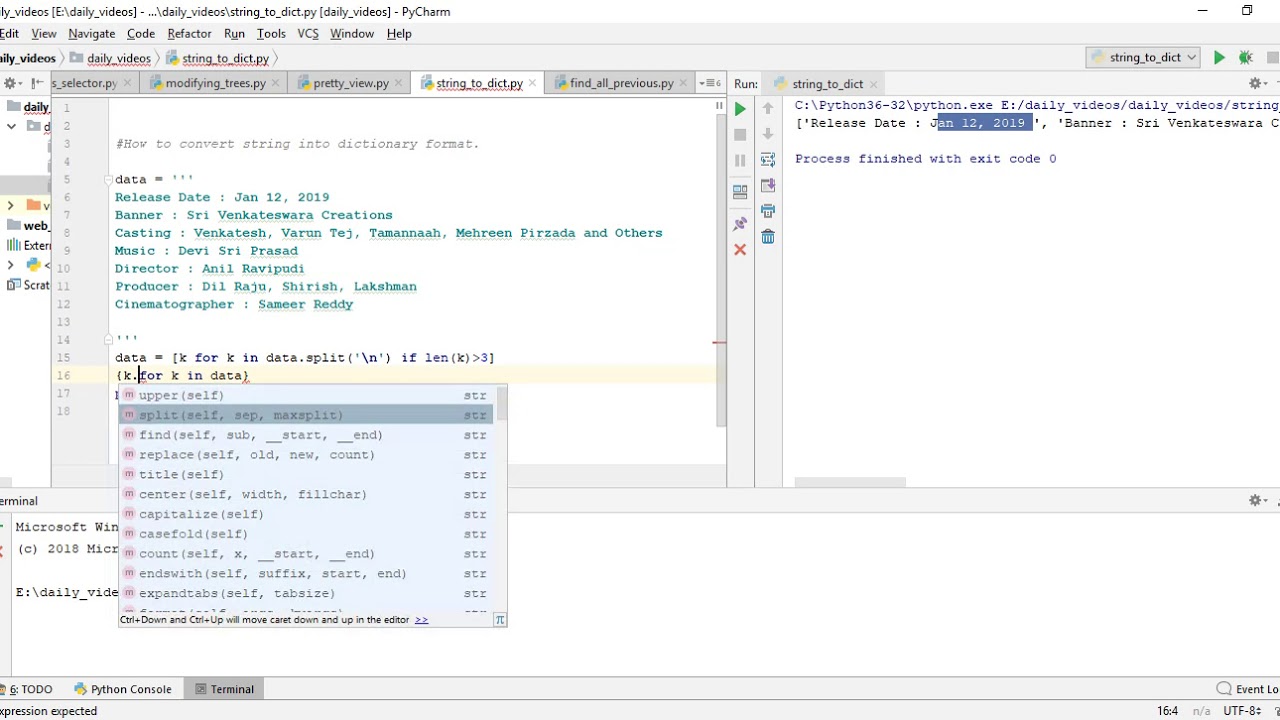
lemma_from_key(key) th_similarity(synsets1, synsets2) h_similarity(synsets1, synsets2) wordnet. wup_similarity(synsets1, synsets2) (form, pos=None) stom_lemmas(tab_file, lang) >>> from import wordnet >>> print(nsets('หนึ่ง')) [Synset('one. s. 05'), Synset('one. 04'), Synset('one. 01'), Synset('one. n. 01')] >>> print(nsets('หนึ่ง')[0]. lemma_names('tha')) [] >>> print(('one. 05')) Synset('one. 05') >>> print(('spy. 01')()) [Lemma(''), Lemma('spy. 01. undercover_agent')] >>> print(('spy. 01'). lemma_names('tha')) ['สปาย', 'สายลับ'] หาคำที่มีจำนวนการใช้งานมากที่สุด from import rank rank(list) คืนค่าออกมาเป็น dict ตัวอย่างการใช้งาน >>> rank(['แมง', 'แมง', 'คน']) Counter({'แมง': 2, 'คน': 1}) แก้ไขปัญหาการพิมพ์ลืมเปลี่ยนภาษา มีคำสั่งดังนี้ texttothai(str) แปลงแป้นตัวอักษรภาษาอังกฤษเป็นภาษาไทย texttoeng(str) แปลงแป้นตัวอักษรภาษาไทยเป็นภาษาอังกฤษ คืนค่าออกมาเป็น str Thai Character Clusters (TCC) PyThaiNLP 1. 4 รองรับ Thai Character Clusters (TCC) โดยจะแบ่งกลุ่มด้วย / เดติด TCC: Mr. Jakkrit TeCho grammar: คุณ Wittawat Jitkrittum () โค้ด: คุณ Korakot Chaovavanich >>> from kenize import tcc >>> ('ประเทศไทย') 'ป/ระ/เท/ศ/ไท/ย' Enhanced Thai Character Cluster (ETCC) นอกจาก TCC แล้ว PyThaiNLP 1.
4 ยังรองรับ Enhanced Thai Character Cluster (ETCC) โดยแบ่งกลุ่มด้วย / >>> from kenize import etcc >>> ('คืนความสุข') '/คืน/ความสุข' Thai Soundex ภาษาไทย เดติด คุณ Korakot Chaovavanich (จาก) กฎที่รองรับในเวชั่น 1. 4 กฎการเข้ารหัสซาวน์เด็กซ์ของ วิชิตหล่อจีระชุณห์กุล และ เจริญ คุวินทร์พันธุ์ - LK82 กฎการเข้ารหัสซาวน์เด็กซ์ของ วรรณี อุดมพาณิชย์ - Udom83 >>> from undex import LK82 >>> print(LK82('รถ')) ร3000 >>> print(LK82('รด')) >>> print(LK82('จัน')) จ4000 >>> print(LK82('จันทร์')) >>> print(Udom83('รถ')) ร800000 Meta Sound ภาษาไทย Snae & Brückner. (2009). Novel Phonetic Name Matching Algorithm with a Statistical Ontology for Analysing Names Given in Accordance with Thai Astrology.
0000', 'as_of_date': '29 มิถุนายน 2561'}, {'last_upd_date': '2018-10-20T05:33:29', 'class_abbr_name': '-', 'reference_period': '10_year', 'performance_type_desc': 'ความผันผวนของกองทุนรวม', 'performance_val': '20. 8700', 'as_of_date': '29 มิถุนายน 2561'}, {'last_upd_date': '2018-10-20T05:33:29', 'class_abbr_name': '-', 'reference_period': '10_year_percentile', 'performance_type_desc': 'ความผันผวนของกองทุนรวม', 'performance_val': '95. 0000', 'as_of_date': '29 มิถุนายน 2561'}] convert Your Json Dict Data to Pandas DataFrame: >>> df = Frame(dj) # df if your Pandas DataFrame Your DataFrame: >>> df as_of_date class_abbr_name last_upd_date \ 0 29 มิถุนายน 2561 - 2018-10-20T05:33:29 1 29 มิถุนายน 2561 - 2018-10-20T05:33:29 2 29 มิถุนายน 2561 - 2018-10-20T05:33:29 3 29 มิถุนายน 2561 - 2018-10-20T05:33:29 performance_type_desc performance_val reference_period 0 ความผันผวนของกองทุนรวม 9. 9300 1_year 1 ความผันผวนของกองทุนรวม 75. 0000 1_year_percentile 2 ความผันผวนของกองทุนรวม 20. 8700 10_year 3 ความผันผวนของกองทุนรวม 95.